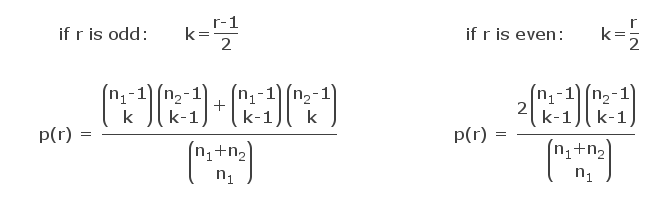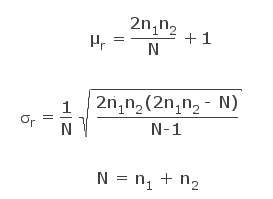| Fundamentals of Statistics contains material of various lectures and courses of H. Lohninger on statistics, data analysis and chemometrics......click here for more. |

|
Home  Statistical Tests Varia Runs Test Statistical Tests Varia Runs Test |
|||||||
  |
|||||||
Runs TestAlthough the term "chance" plays a central role in statistics, it is not a simple decision whether a particular series of numbers is random or not. Here, a multitude of aspects matter, the most important of which are listed as follows:
If we look at a sequence of binary random numbers (e.g. 00101110110111000100110) we may pose the question how many "runs" (sub-sequences consisting of all-ones or all-zeroes) normally occur in a random sequence of a certain number of zeroes and ones. A small number of runs indicates a mixing which is not thorough enough, while a number of runs which is too high points to systematic ordering effects in the sequence. If the number of actually detected runs differs too much from the number of expected runs this may raise the suspicion that the sequence is not random. The example sequence above can be divided into the following runs: 00 | 1 | 0 | 111 | 0 | 11 | 0 | 111 | 000 | 1 | 00 | 11 | 0 The random sequence contains 13 runs with a total of 23 random numbers (11 zeroes, and 12 ones). In order to decide whether the number of found runs is improbable (i.e. the probability that this particular number of runs to occur is below the level of significance) one first has to determine the distribution of runs as a function of the counts of zeroes and ones (n1 and n2). This distribution may be derived from combinatorial calculations. From these considerations we can infer that the probability p(r) of observing r runs, given n1 and n2, can be calculated as follows:
With increasing n1 and n2 the distribution converges to a normal distribution having the mean μr and the standard deviation σr:
In practice this approximation allows to simplify the calculation for samples with n1 and n2 > 20 (which is a substantial numeric advantage, since the binomial coefficients tend to become very high for large samples). However, one has to be careful if n1 and n2 differ too much, as the approximation deviates considerably from the exact values.(1)
Applications of the runs testThe runs test (also called Wald-Wolfowitz test) is primarily used to check the randomness of a random sequence. A prominent application of the runs test is the test for serial correlation of the residuals of a regression model: if the sequence of residuals is non-random the measured data are not completely explained by the function obtained by linear regression.The runs test may also be used to check whether two distributions are equal or not. The idea behind is as follows: if the samples A and B, which are drawn from different distributions, are combined into one big sample, the sorted big sample will only show a random sequence of values originating from A and B if both distribution are equal in all parameters. Otherwise the values of at least one of the two distributions will lump in certain regions, which will result in longer runs and a smaller number of runs than expected. For example, it is obvious that two distributions showing different variances will result in longer runs at the outer parts of the joint distribution. This test is a so-called omnibus test which compares both distributions in all their aspects.
|
|||||||
| Home Statistical Tests Varia Runs Test |
|
||||||