| Grundlagen der Statistik enthält Materialien verschiedener Vorlesungen und Kurse von H. Lohninger zur Statistik, Datenanalyse und Chemometrie .....mehr dazu. |

|
Home  Multivariate Daten Modellbildung Klassifizierung und Diskriminierung Gütemaße für Klassifikatoren Multivariate Daten Modellbildung Klassifizierung und Diskriminierung Gütemaße für Klassifikatoren |
|||||||||||||||||||||
| Siehe auch: Diskrimination und Klassifikation, Predictive Ability, ROC-Kurve | |||||||||||||||||||||
| Search the VIAS Library | Index |   |
||||||||||||||||||||
|
Gütemaße für KlassifikatorenAuthor: Hans Lohninger
Die Überprüfung der Güte eines Klassifikators hängt hauptsächlich vom Typ des Klassifikators ab. Im einfachsten und am häufigsten auftretenden Fall arbeitet man mit binären Klassifikatoren, die nur zwei Ergebnisse erzeugen. Während die Methoden für die Evaluierung binärer Klassifikatoren gut eingeführt und unkompliziert sind, ist die Situation bei Mehrklassen-Verfahren deutlich diffiziler. Die Situation kann außerdem durch die Kombination mehrerer Klassifikatoren noch zusätzlich verkompliziert werden. Die folgende Einführung beschränkt sich daher auf binäre Klassifikatoren. Für binäre Klassifikatoren gilt, dass jede Beobachtung A auf einen von zwei Zuständen abgebildet wird (z.B. JA und NEIN, oder 0 und 1, oder gesund und krank). Die binäre Antwort des Klassifikators kann nun in Bezug auf die (unbekannte) Realität entweder korrekt oder falsch sein. Die Ergebnisse der Klassifikation werden in einer Klassifikationstabelle oder Wahrheitsmatrix (engl. confusion matrix) zusammengefasst; diese enthält die Anzahl aller Beobachtungen in den vier möglichen Kombinationen aus Klassifizierungsergebnis und Wirklichkeit. Falls das Klassifikationsergebnis richtig ist, spricht man von "richtig positiv" und "richtig negativ", abhängig davon zu welcher Klasse die Beobachtung tatsächlich gehört. Falls der Klassifikator eine falsche Antwort liefert, spricht man von einer "falsch positiven" bzw. "falsch negativen" Entscheidung:
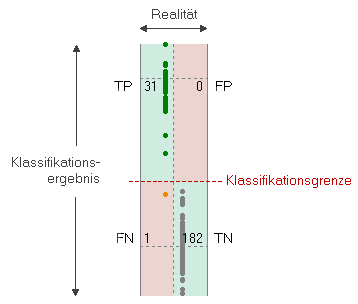
Korrekte Klassifikationsergebnisse stehen in der Tabelle in der Hauptdiagonale (grüne Bereiche), fehlerhafte Ergebnisse in der Nebendiagonale (rote Bereiche). Einige Klassifikationsmodelle (wie z.B. die Diskriminanzanalyse) erzeugen primär kontinuierliche Schätzwerte, die mit einer Klassifikationsgrenze verglichen werden um das binäre Endergebnis zu bekommen. Im Fall eines kontinuierlichen Klassifikationsergebnisses kann man die Klassifikationstabelle visualisieren, in dem man den kontinuierlichen Output des Klassifikators auf einer Achse plottet und die tatsächliche Klasse (die "Wirklichkeit") auf der anderen Achse. Die Klassifikationsgrenze wird durch eine strichlierte Linie angezeigt:
Dieses Diagramm erlaubt es, die Verlässlichkeit eines Klassifikators visuell zu überprüfen, in dem man auf die Distanz und die Datendichte jener Beobachtungen schaut, die nahe der Entscheidungsgrenze liegen. Um die Klassifikatorgüte auf eine formalere und quantitative Ebene zu führen, wurden mehrere Maßzahlen definiert. Die Tabelle unten bedient sich folgender Notation: N .... Gesamtzahl der Beobachtungen
|
|||||||||||||||||||||
| Home Multivariate Daten Modellbildung Klassifizierung und Diskriminierung Gütemaße für Klassifikatoren |
|
||||||||||||||||||||


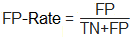
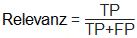




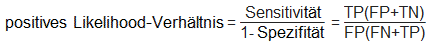

Last Update: 2016-12-12