| Grundlagen der Statistik enthält Materialien verschiedener Vorlesungen und Kurse von H. Lohninger zur Statistik, Datenanalyse und Chemometrie .....mehr dazu. |

|
Home  Multivariate Daten Modellbildung Klassifizierung und Diskriminierung Clusteranalyse k-Means Clusteranalyse Multivariate Daten Modellbildung Klassifizierung und Diskriminierung Clusteranalyse k-Means Clusteranalyse |
|||||||||
| Siehe auch: Clusteranalyse | |||||||||
| Search the VIAS Library | Index |   |
||||||||
|
k-Means ClusteranalyseAuthor: Hans Lohninger
Eines der ältesten und robustesten Clusteranalyseverfahren ist k-Means, bei dem in iterativer Weise, mit zufälligen Clusterzentren beginnend, eine vorgegebene Zahl an Cluster gefunden wird. k-Means Clustering gehört zu den einfachsten Austauschverfahren. Mathematisch gesehen, entspricht k-Means Clustering einer Optimierung bei der die Zielfunktion
Algorithmus
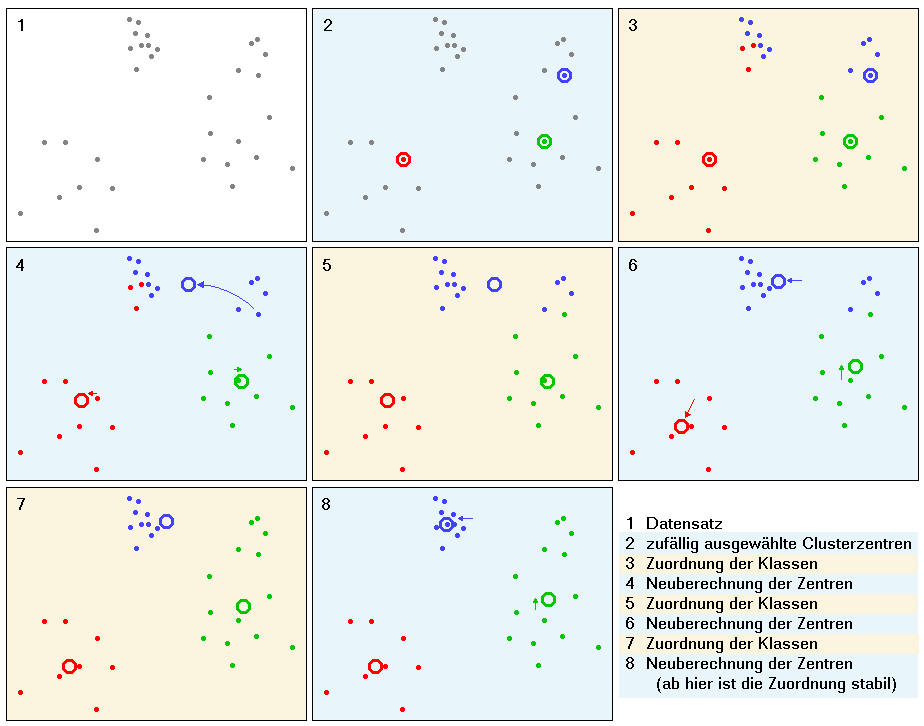
Die folgende Abbildung zeigt die Verschiebung der Clusterzentren für ein einfaches zweidimensionales Beispiel:
Nachteile des Verfahrens Neben dem Vorteil der einfachen und schnellen Implementierung hat das k-Means-Verfahren auch ein paar Nachteile, die nicht übersehen werden sollten:
|
|||||||||
| Home Multivariate Daten Modellbildung Klassifizierung und Diskriminierung Clusteranalyse k-Means Clusteranalyse |
|
||||||||

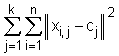
Last Update: 2019-04-09