| Fundamentals of Statistics contains material of various lectures and courses of H. Lohninger on statistics, data analysis and chemometrics......click here for more. |

|
Home  Multivariate Data Modeling PLS Partial Least Squares Regression Multivariate Data Modeling PLS Partial Least Squares Regression |
|
| See also: Principal Component Regression, Modeling with latent variables, Evaluating the performance of PLS-DA |   |
PLS - Partial Least Squares RegressionPartial least squares (PLS) models are based on principal components of both the independent data X and the dependent data Y. The central idea is to calculate the principal component scores of the X and the Y data matrix and to set up a regression model between the scores (and not the original data).
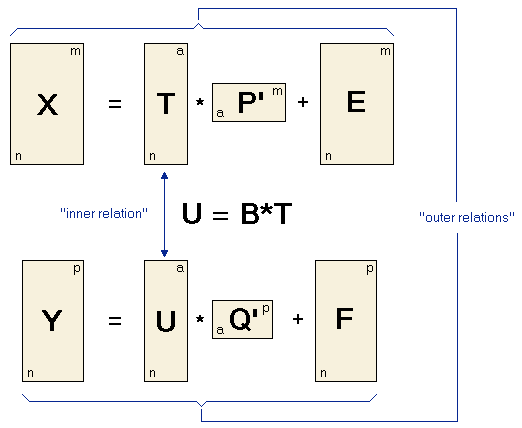
Thus the matrix X is decomposed into a matrix T (the score matrix) and a matrix P' (the loadings matrix) plus an error matrix E. The matrix Y is decomposed into U and Q and the error term F . These two equations are called outer relations. The goal of the PLS algorithm is to minimize the norm of F while keeping the correlation between X and Y by the inner relation U = BT . The important point when setting up a PLS model is to make a decision for the optimum number a of principal components involved in the PLS model. While this can be done from variation criteria for other models, for PLS the optimum number of components has to be determined empirically by cross validation of the PLS model using an increasing number of components. The model with the smallest PRESS value can be regarded as the "best" model. Please note that there are several different algorithms of performing a partial least squares regression having different names and showing slight variations in the obtained results. An often used iterative algorithm is the NIPALS ("nonlinear iterative partial least squares") algorithm, which is a version of the power method for extracting eigenvectors of a matrix. PLS may also be calculated by singular value decomposition, which is usually much faster than NIPALS. |
|
| Home Multivariate Data Modeling PLS Partial Least Squares Regression |
|