| Fundamentals of Statistics contains material of various lectures and courses of H. Lohninger on statistics, data analysis and chemometrics......click here for more. |

|
Home  Multivariate Data Modeling Classification and Discrimination Cluster Analysis k-Means Clustering Multivariate Data Modeling Classification and Discrimination Cluster Analysis k-Means Clustering |
|||||||||
| See also: KNN classification |   |
||||||||
k-Means ClusteringK-means clustering is one of the simplest exchange methods. It may be used for larger datasets as it is rather quick if only a few cluster centers are involved. K-means clustering requires the number of clusters k to be specified by the user. It may be used for larger datasets as it is rather quick if only a few cluster centers are involved. K-means clustering requires the number of clusters k to be specified by the user.
From a mathematical viewpoint k-means clustering is equivalent to an minimisation of the target function
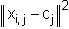 is the distance between the datapoint i and the cluster center j. is the distance between the datapoint i and the cluster center j.
Algorithm
Disadvantages of the k-means algorithm Apart from the simple and quick implementation the k-means procedure exhibits a few disadvantages which must not be overlooked:
|
|||||||||
| Home Multivariate Data Modeling Classification and Discrimination Cluster Analysis k-Means Clustering |
|
||||||||