| Grundlagen der Statistik enthält Materialien verschiedener Vorlesungen und Kurse von H. Lohninger zur Statistik, Datenanalyse und Chemometrie .....mehr dazu. |

|
Home  Multivariate Daten Modellbildung Test von Modellen Addition von Rauschen Multivariate Daten Modellbildung Test von Modellen Addition von Rauschen |
|
| Siehe auch: Generalisierung und Overtraining | |
| Search the VIAS Library | Index |   |
|
Addition von RauschenAuthor: Hans Lohninger
Generalisierung ist ein sehr wichtiger Aspekt bei der Erstellung von nicht
linearen Modellen (besonders, wenn neuronale Netzwerke eingesetzt werden). Um
gut arbeitende Modelle zu erstellen, muss man die Verallgemeinerungsfähigkeit
des Modells überprüfen. In dieser Hinsicht kann Verallgemeinerung als
Rauschunempfindlichkeit gesehen werden: Das Modell sollte sich selbst nicht an
vorhandenes Rauschen im System anpassen. Dieser Aspekt bringt uns auf den
Gedanken, dass das Verallgemeinerungsverhalten eines Modells durch die steigende
Zugabe von Rauschen zu den Trainingsdaten - bei gleichzeitiger
Überprüfung der Stabilität des Modells - getestet werden kann. Um den Verallgemeinerungstest durchführen zu können, benötigen wir zwei Maße:
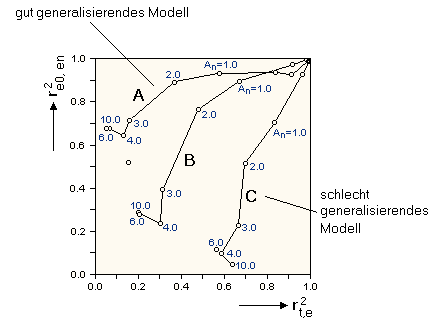
In der Abbildung oben wird die Abhängigkeit von
r2t,e und r2e0,en von
verschiedenen Rauschpegeln An für drei unterschiedliche Netze
gezeigt. Kurve A (gute Verallgemeinerung): 400 Datenpunkte, 15 verdeckte
Neuronen; Kurve B (mittlere Verallgemeinerung): 200 Datenpunkte, 38 verdeckte
Neuronen; Kurve C (schlechte Verallgemeinerung): 100 Datenpunkte, 70 verdeckte
Neuronen.
|
|
| Home Multivariate Daten Modellbildung Test von Modellen Addition von Rauschen |
|

Last Update: 2012-10-08