| Fundamentals of Statistics contains material of various lectures and courses of H. Lohninger on statistics, data analysis and chemometrics......click here for more. |

|
Home  Bivariate Data Curve Fitting Extrapolation Bivariate Data Curve Fitting Extrapolation |
|||
| See also: Neural Networks - Extrapolation, Common Questions about ANNs, Interpolation, Generalization and Overtraining |   |
||
ExtrapolationWhen fitting curves to data one has to distinguish two fundamentally different regions: the range of data where interpolation occurs and the range of extrapolation.
In general, by interpolation we understand the estimation of unknown data points between known (measured) data values. However, this definition does not suit well in most practical circumstances - think of two neighboring data points with a large unknown region between them; this scenario does not allow any serious interpolation. In consequence, we should change our initial definition of interpolation and replace it by referring to the local density of known data. If this density exceeds a certain threshold we may talk of interpolation. Remark: in addition, some authors make a distinction between interpolation and approximation. Interpolation then requires the known data points to be located on the interpolating curve, while approximation allows this curve to be located "close" to the known points (in the sense of linear regression). However, the boundaries between strict interpolation and approximation may become blurred if we think of penalized splines, for example. Extrapolation We talk of extrapolation, if values have to be estimated in regions of the data space where no known data points ("training data") are available, or in other words, where the density of the data space is (close to) zero. The validity of extrapolated data depends both on the distance to the closest region of known data, and on the type of model which is used for extrapolation. In general, the reliability of extrapolated values decreases with increasing number of freedoms of the fitted model. If we use a simple linear regression for the extrapolation the extrapolated values will be reliable in a broader region than it will be the case for penalized splines or even neural networks.
|
|||
| Home Bivariate Data Curve Fitting Extrapolation |
|
||
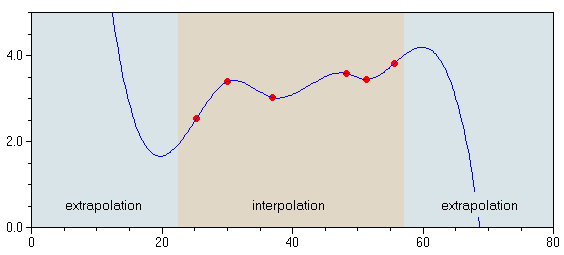
 The figure at the right compares the extrapolation results of a neural network to simple linear regression.
The figure at the right compares the extrapolation results of a neural network to simple linear regression.