| Grundlagen der Statistik enthält Materialien verschiedener Vorlesungen und Kurse von H. Lohninger zur Statistik, Datenanalyse und Chemometrie .....mehr dazu. |

|
Home  Allgemeine Bearbeitungsschritte Datenvorverarbeitung Transformation von Daten-Räumen Allgemeine Bearbeitungsschritte Datenvorverarbeitung Transformation von Daten-Räumen |
|
| Siehe auch: Transformation von Datenräumen - Beispiel: Massenspektrometrie | |
| Search the VIAS Library | Index |   |
|
Transformation von DatenräumenAuthor: Hans Lohninger
Wenn Modellierungstechniken auf hochdimensionale multivariate Probleme angewendet werden, versagen die meisten Methoden wegen der Komplexität des Datenraums. Obwohl es eine Beziehung zwischen den Daten gibt, kann sie nicht modelliert werden, weil die Beziehung von zu vielen Variablen verdeckt wird (oder die Beziehung ist über eine zu große Zahl an Variablen verteilt). In diesem Fall kann eine spezielle Vorverarbeitung der Daten die Ergebnisse beträchtlich verbessern. Wichtig bei der Vorverarbeitung der Daten ist, dass das Wissen über die Daten, das man besitzt, miteinbezogen wird. Allgemein gesprochen, ist die Datenvorverarbeitung also ein Mittel, um spezifisches Wissen über die Daten einzuführen. Im mathematischen Sinn sollte die Vorverarbeitung den Datenraum auf eine Weise transformieren, dass (1) weniger Variablen für das Modell benötigt werden und (2) die Beziehung zwischen den Deskriptorvariablen und den Zielvariablen einfacher wird. Ein extremes, aber verständliches Beispiel soll das Prinzip der
Transformation des Datenraums demonstrieren. Stellen Sie sich vor, Sie haben
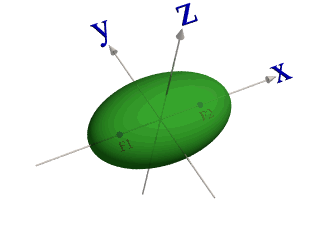
zwei Klassen von Objekten, die mittels drei Parametern x1,
x2 und x3 beschrieben werden. Die Klasse 1 formt
einen Cluster, der eine Form ähnlich eines Ellipsoids hat. Die Objekte
der Klasse 2 liegen alle außerhalb dieses Ellipsoids.
Dies ist ein einfaches Beispiel für ein Klassifikationsproblem, das nur durch die Verwendung von nicht linearen Methoden gelöst werden kann und nicht durch die Verwendung von linearen Methoden, wie multiple lineare Regression. Als Nächstes transformieren Sie den Datenraum (x1, x2, x3) in einen anderen Raum, der durch zwei neue Deskriptoren l1 und l2 definiert ist. Die neuen Deskriptoren spezifizieren den Abstand der Objekte zu den Brennpunkten des Ellipsoids F1 und F2. Wenn man die Klasse 1 im Raum (l1-l2) darstellt, wird der elliptische Cluster der Klasse 1 zu einer rechteckigen Region mit einer einzigen (!) linearen Separierungslinie transformiert.
Dieses einfache Beispiel zeigt klar, dass die Transformation des
Datenraums ein gegebenes Problem beträchtlich vereinfachen kann. Tatsächlich
haben wir den Datenraum mit dem Wissen, dass der Cluster 1 ein Ellipsoid formt,
auf solche Weise transformiert, dass (1) die Anzahl der notwendigen Variablen
verringert wurde und (2) die nicht lineare Klassifikationsaufgabe in ein
lineares Problem übergeführt wurde (das durch die Anwendung bekannter
Methoden einfach zu lösen ist).
|
|
| Home Allgemeine Bearbeitungsschritte Datenvorverarbeitung Transformation von Daten-Räumen |
|

Last Update: 2012-10-16