| Grundlagen der Statistik enthält Materialien verschiedener Vorlesungen und Kurse von H. Lohninger zur Statistik, Datenanalyse und Chemometrie .....mehr dazu. |

|
Home  Multivariate Daten Modellbildung PLS PLS Regression Multivariate Daten Modellbildung PLS PLS Regression |
|
| Siehe auch: Modellierung mit latenten Variablen | |
| Search the VIAS Library | Index |   |
|
PLS RegressionAuthor: Administrator
PLS-Modelle ("Partial Least Squares") basieren auf den Hauptkomponenten sowohl der unabhängigen Variablen X, als auch der abhängigen Variablen Y. Die zentrale Idee besteht darin, für die Matrices X und Y die Hauptkomponenten getrennt zu berechnen und ein Regressionsmodell zwischen den Scores der Hauptkomponenten (und nicht den Originaldaten) zu erstellen.
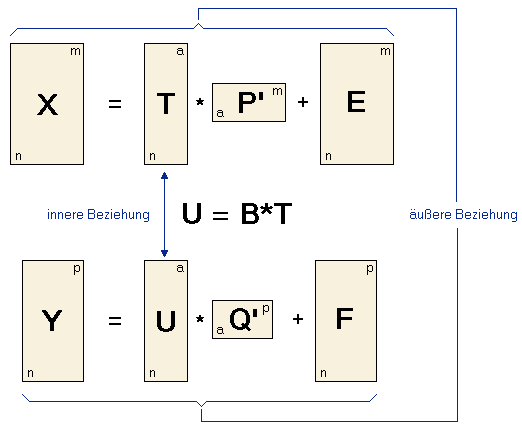
Dazu zerlegt man die Matrix X in eine Matrix T (die "Score"-Matrix) und eine Matrix P' (die "Loadings"-Matrix) plus einer Fehlermatrix E. Die Matrix Y wird in die Matrizen U und Q und den Fehlerterm F zerlegt. Diese zwei Gleichungen nennt man die "äusseren Beziehungen". Das Ziel von PLS ist es, die Norm von F zu minimieren und gleichzeitig eine Korrelation zwischen X und Y zu erhalten, in dem die Matrizen U und T in Beziehung zueinander gesetzt werden: U = BT. Diese Gleichung nennt man auch die "innere Beziehung". Ein wichtiger Punkt bei PLS ist die Entscheidung darüber, welche Zahl von Hauptkomponenten in die PLS-Berechnung einbezogen wird. Während das bei anderen Verfahren über Variationskriterien entschieden werden kann, muss die optimale Zahl der Hauptkomponenten bei PLS empirisch mit Hilfe der Kreuzvalidierung bestimmt werden. Das Modell mit dem kleinsten PRESS kann als das "beste" Modell angesehen werden. Bitte beachten Sie, dass es einige verschiedene Algorithmen zur Berechnung von PLS-Modellen gibt, die unterschiedliche Namen haben und kleine Unterschiede in den Ergebnissen liefern. Ein iteratives Verfahren das oft verwendet wird ist der so genannte NIPALS-Algorithmus ("nonlinear iterative partial least squares"), der eine Version der Potenzmethode zur Extraktion von Eigenwerten darstellt. PLS-Modelle können auch mit Hilfe der SVD berechnet werden, die im allgemeinen wesentlich schneller als der NIPALS-Algorithmus sind.
|
|
| Home Multivariate Daten Modellbildung PLS PLS Regression |
|
Last Update: 2012-10-08