| Grundlagen der Statistik enthält Materialien verschiedener Vorlesungen und Kurse von H. Lohninger zur Statistik, Datenanalyse und Chemometrie .....mehr dazu. |

|
Home  Multivariate Daten Modellbildung Multiple Regression Logistische Regression Multivariate Daten Modellbildung Multiple Regression Logistische Regression |
|
| Siehe auch: Lineare Diskriminanzanalyse | |
| Search the VIAS Library | Index |   |
|
Logistische RegressionAuthor: Hans Lohninger
Versucht man ein Regressionmodell zu erstellen, dessen abhängige Variable (Zielvariable) dichotom ist (also nur zwei Werte kennt, z.B. tot/lebendig, oder ja/nein), so kann dies mit der linearen Regression schon aus formalen Gründen nicht funktionieren, falls die unabhängigen Variablen metrisch skaliert sind (was meist der Fall ist):
In solchen Fällen kann man versuchen, statt der Zielvariablen die Chance, dass eine bestimmte Ausprägung der Zielvariable eintritt zu schätzen. Da es sich bei der Zielvariable y um eine dichotome Variable handelt, gibt es nur zwei Zustände (z.B. 0 und 1). Kennt man die Wahrscheinlichkeit für einen Zustand, ergibt sich damit auch die Wahrscheinlichkeit für den anderen Zustand: P(y=1) = 1 - P(y=0) Die Chance für einen Zustand ergibt sich damit aus dem Verhältnis der beiden Wahrscheinlichkeiten:
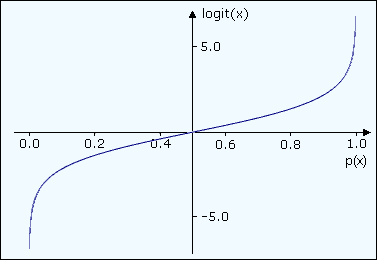
Für die Modellierung verwendet man den Logarithmus der Chance und bezeichnet diese Funktion als "logit":
Die Logit-Funktion transformiert die Wahrscheinlichkeit des Auftretens einer bestimmten Ausprägung so, dass sich für das sichere Auftreten des einen Zustandes ein Wert von minus unendlich ergibt, für das sichere Auftreten des anderen Zustands plus unendlich und für gleiche Chancen ein Wert von null.
Ausgehend von der klassischen Regressionsgleichung wird nun die Zielvariable Y durch die Logit-Funktion ersetzt: logit(y) = a0 + a1x1+ a2x2 + a3x3 + .... Das Problem bei der Parametrisierung der logistischen Regressionsgleichung ist nun, dass man den klassischen Regressionsansatz nach der Methode der kleinsten Quadrate nicht verwenden kann, da die möglichen unendlichen Werte der Logit-Funktion dies verhindern (einerseits aus numerischen Gründen, und andererseits einfach aufgrund des Hebeleffekts). Die Abschätzung der Parameter erfolgt mit Hilfe der Maximum Likelihood-Methode, die eine Verallgemeinerung der Methode der kleinsten Quadrate darstellt (und für den Fall, dass die Deskriptoren normalverteilt sind, in diese übergeht).
|
|
| Home Multivariate Daten Modellbildung Multiple Regression Logistische Regression |
|
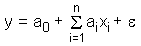
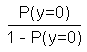

Last Update: 2012-10-09